Today I learned you can set default output options for the dig command by creating a .digrc file in your home directory.
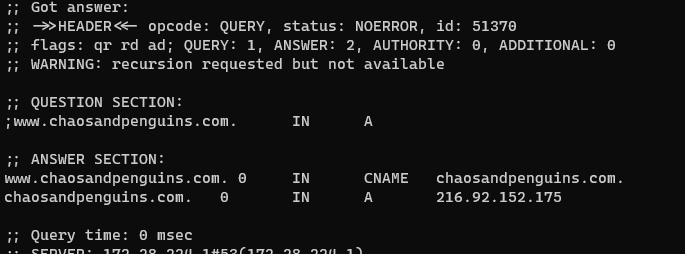
Ordinally, running the command dig www.chaosandpenguins.com, the result is this rather hefty block of text.
$ dig www.chaosandpenguins.com
; <<>> DiG 9.16.1-Ubuntu <<>> www.chaosandpenguins.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40732
;; flags: qr rd ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 0
;; WARNING: recursion requested but not available
;; QUESTION SECTION:
;www.chaosandpenguins.com. IN A
;; ANSWER SECTION:
www.chaosandpenguins.com. 0 IN CNAME chaosandpenguins.com.
chaosandpenguins.com. 0 IN A 216.92.152.175
;; Query time: 0 msec
;; SERVER: 172.28.224.1#53(172.28.224.1)
;; WHEN: Wed Nov 16 23:13:00 EST 2022
;; MSG SIZE rcvd: 136That’s a whole lot of text. So let’s add a couple options. +noall turns off everything. Running dig www.chaosandpenguins.com +noall would literally return nothing at all. To bring back the answer section (which is what I’m interested in most of the time), you add the +answer option.
$ dig www.chaosandpenguins.com +noall +answer
www.chaosandpenguins.com. 0 IN CNAME chaosandpenguins.com.
chaosandpenguins.com. 0 IN A 216.92.152.175That’s much more compact , but getting it requires some extra typing. And I want that version of the output most of the time, so wouldn’t it be nice if there was to make that the default?
This is where the .digrc file comes in. You create it in your home directory and just put in a single line containing the options you want. So, to make +noall +answer the defaults, I just run this command:
$ echo +noall +answer > ~/.digrcAnd now when I run dig www.chaosandpenguins.com without any options, here’s the default output:
$ dig www.chaosandpenguins.com
www.chaosandpenguins.com. 0 IN CNAME chaosandpenguins.com.
chaosandpenguins.com. 0 IN A 216.92.152.175