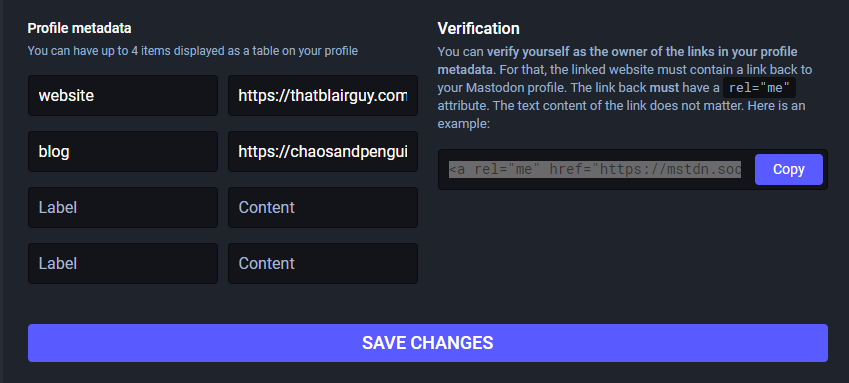
I have a parrot – her name’s Terry Datyl. I also have a bunch of house plants. These two statements are connected, though perhaps not in an obvious manner.
Part of my morning routine is to go downstairs and uncover Terry’s cage, turn on the light next to the cage, and then turn on the radio so she has a “flock” of sorts to hang out with. Next, I turn on the various grow lights for the house plants.
That was the routine for several years. I’d connect lamp timers when I was gone for the weekend and it all worked fairly well.
A while back, I thought it might be interesting to have Home Assistant take over turning on the plant lights. Ideally, a trigger would fire when Terry’s lamp was turned on and I could just put some smart plugs on the plant lights.
Have you ever tried shopping for a smart lamp? They do exist, but it mostly seems like accent lighting. I haven’t found anything which was meant to illuminate a room and nothing that really fit into our décor anyhow.
So, what I hit on was the idea of connecting the existing lamp (the “control lamp” if you will) to a TP-Link HS110 smart plug. In addition to the vanilla on/off capability, this particular plug also reports power usage. (Note: This may no longer be possible with TP-Link smart plug. A 2020 firmware update removed an API Home Assistant relies on. The general concepts however should still apply to other smart plugs with power monitoring capabilities.)
So, step one was to connect the plant lights to smart plugs. I used TP-Link plugs because I already had them, but you can use others. (As noted above, that may indeed be necessary.)
Next, I created two “scenes” in Home Assistant. One in which all the plant lights were on, and another where they were all off. (Creatively named, “Plants Off” and “Plants On.”)
Next up was setting up the HS110 plug that would be running the show. In addition to an on/off state, the HS110 exposes several state “attributes”: voltage, current, and the current (meaning “right now”) power in watts. This last one is what we’re interested in.
State attributes vary from one device to the next, so Home Assistant doesn’t really have a good way to expose them directly. Instead, you can expose the values you want via sensor templates.
Go into the Home Assistant config directory and edit the sensor.yaml file (creating it if necessary). Here’s the entry I created to read how many watts Terry’s lamp is using
- platform: template
sensors:
terry_s_lamp_watts:
friendly_name_template: "{{ states.switch.terry_s_lamp.name}} Current Consumption"
value_template: '{{ states.switch.terry_s_lamp.attributes["current_power_w"] | float }}'
unit_of_measurement: 'W'
Note: the friendly_name_template and value_template entries are one line apiece (one day I’ll tweak this theme to better accommodate code snippets). This is just a plain YAML file so all the usual editing concerns apply.
This shows up in Home Assistant as a numeric sensor with the name sensor.terry_s_lamp_watts (you may need to restart for it to show up). It’s a floating-point number, so we’ll have to accommodate for that in the automation.
You’ll need to know how much power the lamp draws in its on and off states so in the Home Assistant UI, go to Developer Tools > States and select the entity sensor.terry_s_lamp_watts (substituting your sensor’s name, of course) and if all is right, the current power draw will show up in the “State” field. Turn the lamp on and off (using the the lamp’s switch, not the smart switch) and note the values (click the “refresh” icon to get the new value).
The final step then is to create two automations. Mine are named “Terry’s lamp turns on” and “Terry’s lamp turns off.”
For the “on” automation, I used a numeric state trigger on the entity sensor.terry_s_lamp_watts. The power usage tends to vary over time as the bulb warms and cools, so I chose 9 watts as a value that comfortably below the lamp’s “on” state while still higher than the lamp’s “off” state. (Similarly, the “off” automation uses a value of 5 watts, which allowed me to turn on the radio that was plugged into the same smart plug without triggering the automations.)
For both automations, the only action is to activate the appropriate scene. Either scene.plants_on or scene.plants_off.
At this point, you now have a single lamp which uses its existing switch to control other lights. (This means, no worries about guests messing things up by not using the smart switch – this adds smarts to the “dumb” lamp.)
Latency
With the HS110 smart plug on the control lamp, there’s a delay of up to 30 seconds between the time the control lamp changes state and when the automation will run. That’s because TP-Link smart plugs don’t actively report their state and Home Assistant has to use “local polling” to check whether the switch’s state has changed since the last time it was set. In order avoid flooding the local network with traffic, Home Assistant only checks the device’s status once every 30 seconds. Devices from other manufacturers may behave differently.
To solve this using the HS110 device, I added an additional automation, using a trigger type of “Time Pattern” with Hour and Minutes left blank and Seconds set to /3, the automation runs every 3 seconds. I then set the action manually, in the UI’s YAML editor
service: homeassistant.update_entity
data: {}
entity_id:
- switch.terry_s_lamp
- switch.office_light
This action causes Home Assistant to update the state for both the switch.terry_s_lamp (the control lamp) and switch.office_light (the smart switch in my home office, also a TP-Link device).